Jupyter Notebook (previously called IPython Notebook ) is a web application that allows you to create and share documents that contains Python code that can be executed along with rich text (Markdown), interactive plots, equations (LaTex), images, videos and other elements. This tutorial shows you how to visualize your data in Jupyter Notebook with the help of two Python libraries - Pandas and Matplotlib.
Pandas provide fast, flexible and easy to use data structures for data analysis and Matplotlib is used visualize data using charts such as bar charts, line plots, scatter plots and many more.
Foreword
This tutorial is aimed at people who are familiar with Python Language and creating simple Jupyter Notebooks. The easiest way to try out the examples in this tutorial is by installing Anaconda (the Python data science platform) and launch JupiterLab from Anaconda Navigator. JupiterLab is a feature rich GUI environment for creating Jupyter Notebooks.
About the Dataset
The data set used for plotting the graphs in this article is called "Price Paid Data" which is published by the UK government and contains the residential property sales in England and Wales.
To download Price Paid Data - latest month file in CSV format, click here.
You can also find detailed explanation for each column in the Price Paid Data on the link here.
Reading data from CSV
The first step is to import the data from the CSV file that we downloaded. This can be done easily using the read_csv() function from the Pandas library. If you had a look at the CSV file you might have noticed that there are no column names to describe what each data means. So we will pass three arguments to the read_csv function - first is the filename and path of the CSV file, second is an array of strings to use as column names for the dataset and the third argument to say that the sale date column must be parsed as a date. Here is the Python code to do this.
import pandas as pd
#File path to the csv file
csv_file = "./pp-monthly-update-new-version.csv"
# Read csv file into dataframe
df = pd.read_csv(csv_file, names = ["TID","Price","Sale Date", "Postcode",
"Property Type","New Build","Tenure",
"PAON","SAON","Street","Locality",
"Town/City","District","County",
"PPD Category","Record Status"],
parse_dates= ["Sale Date"])
# Print first 5 rows in the dataframe
df.head()

You can use the df.dtypes attribute to check the data types of the columns.
Filtering Data
Next we will filter the data to get all the transaction for a particular year and month ( say August 2018 for example). We will only keep transactions of type "A" (Additions) in the data frame and get rid of Changes and Deletions. And for the sake of simplicity we will also remove transactions for property type "O" (Other) and focus only on Detached ("D"), Semi Detached ("S"), Flats ("F") and Terraced ("T") houses.
#Select only record type A and property type not "O" df = df.loc[df['Record Status'] == 'A'] df = df.loc[df['Property Type'] != 'O'] # Select transactions for August 2018 df = df[(df["Sale Date"].dt.year==2018) & (df["Sale Date"].dt.month==8)]
Line Plot
First and foremost you need to add the below two lines of code which is to import the matplotlib.pyplot and to set the output of the plotting to be displayed inline.
import matplotlib.pyplot as plt %matplotlib inline
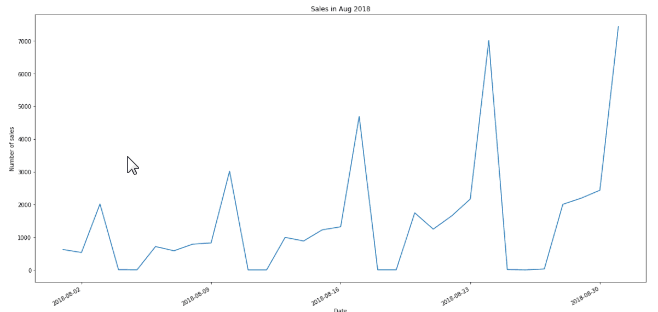
We can now create our first chart which is a simple line plot that shows the number of house sales (transactions) completed each day in August 2018. For this we call the value_counts() function which return the count of transactions for each sale date.
# Daily sales volume for august 2018
daily_sales_vol = df["Sale Date"].value_counts()
daily_sales_vol.plot()
plt.title('Sales in Aug 2018')
plt.ylabel('Number of sales')
plt.xlabel('Date')
plt.rcParams['figure.figsize'] = (20.0, 10.0)
Bar Chart
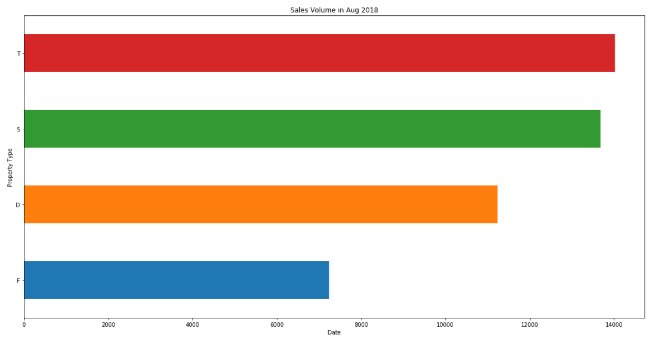
The next chart we create is a bar chart of the total sales volume by Property type. To plot a horizontal bar chart, we set the argument kind='barh'. The sort_values() function sorts the values in ascending order by default.
# Number of residential property transactions in Aug 2018 by property type
sales_by_type = df["Property Type"].value_counts()
sales_by_type.sort_values().plot(kind='barh')
plt.title('Sales Volume in Aug 2018')
plt.ylabel('Property Type')
plt.xlabel('Date')
Stacked Bar Chart
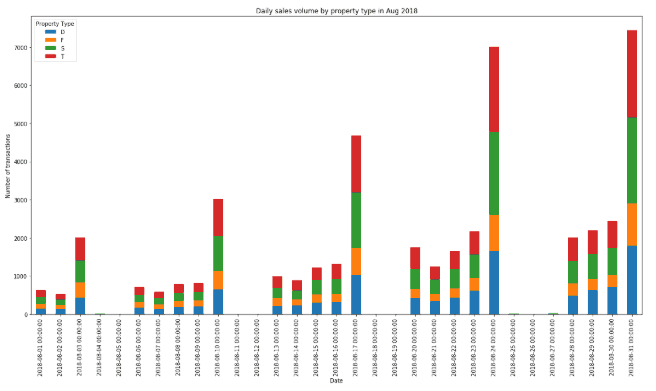
A stacked bar chart is similar to a bar chart except that the bars for the sub-segments are stacked up. This provides a good visual representation of how each sub-segment contributes towards the overall sum. In this example we create a stacked bar graph which shows daily number of sales for each property type.
- Groupby function groups the data by sale date and property type.
- Size() function will count the number of records for each property type in the grouped data.
- Unstack() function switches Property Type rows to columns.
# Daily sales volume by property type
df.groupby(['Sale Date','Property Type']).size().unstack().plot(kind='bar', stacked=True)
plt.title('Daily sales volume by property type in Aug 2018')
plt.ylabel('Number of transactions')
plt.xlabel('Date')
Box Plot
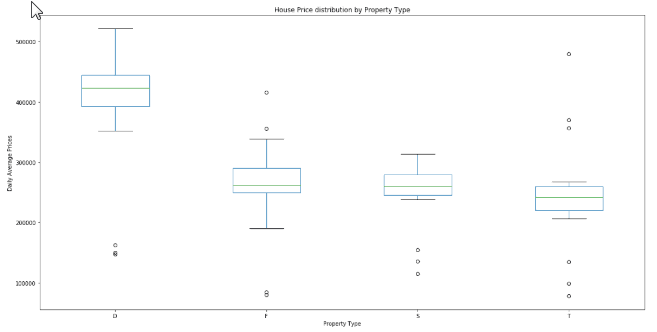
Box plot, also called as box and whisker plot, is a way of showing the distribution of data in a five-number summary.
The below code will create a box plot which shows the price distribution for all the four different property types.
# Price distribution box plot
df.groupby(['Sale Date', 'Property Type'])['Price'].mean().unstack().plot(kind="box")
plt.title('House Price distribution by Property Type')
plt.ylabel('Daily Average Prices')
plt.xlabel('Property Type')
The data is grouped by sale date and property type and the daily average price for each property type is calculated. You then have to unstack the data and plot it.
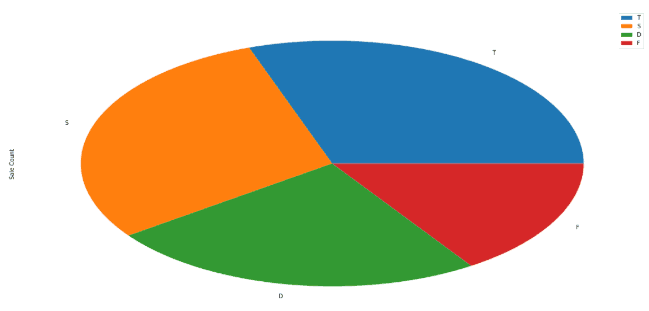
Pie Chart
Pie chart is a good way of showing relative proportion of data segments. For example a pie chart of the monthly sales volumes can reveal which type of property has more number of sales. Here is how to draw a pie chart.
#Pie Chart sale_volume = pd.DataFrame(df['Property Type'].value_counts()) sale_volume.columns=['Sale Count'] sale_volume.plot(kind='pie', y='Sale Count')
Summary
In this tutorial we demonstrated how to visualize a dataset in Jupyter Notebook using Pandas and Matplotlib libraries. We created few different types of plots that are relevant to the dataset that we were working with. Furthermore, you can also create other plot types such as Scatter plots, histograms and Area plots using Pandas and Matplotlib provided that you have a suitable dataset. Hope this tutorial gives you a kick start for some exciting Jupyter Notebook projects.



