Web scrapping is a technique by which a computer program automatically extracts information from a web page.
Scraping involves the following sequence of steps:
- Send a HTTP request to get the web page
- Parse the response to create a structured HTML object
- Search and extract the required data from the HTML object
Python script for web scrapping
The rest of this article will guide you through creating a simple Python script for scraping data from a website. This script extracts the news headlines from Google News website.
Pre-requisites
1. Python
Obviously, you need to have Python. If you don't already have it, then download and install the latest version for your Operating System from here
2. Lxml
lxml is a library for processing XML and HTML easily. It is a Pythonic binding for libxml2 and lbxslt thereby combining the power of these two libraries with the simplicity of a Python API. To install lxml, the best way is to use pip package management tool. Run the command
pip install lxmlIf the installation fails with an error message that ends like ...failed with error code 1 the most likely reason is you may not have the necessary development packages, in which case run the following command:
set STATICBUILD=true && pip install lxml3. Requests
Requests is a library for sending HTTP requests. Just like Lxml, you can install Requests using pip
pip install requestsProgram Flow
Step 1: The first step in the program is to send a HTTP request and get the entire page contents to an object named response.
response = requests.get('http://news.google.com')
Step 2: In the next step the status code of response object is checked to see if the request succeeded or not.
if (response.status_code == 200):
Step 3: The response text is then parsed to form a tree structure
pagehtml = html.fromstring(response.text)
Step 4: Inspect the page elements using Developer Tools in your browser and identify the path to HTML element that contains the data. For example in the figure below, assume the data you need to extract is titles such as "Jeremy Corbyn's seven U-turns ahead of Labour conference speech - live" then the path for such elements will be:
//h2[@class="esc-lead-article-title"]/a/span[@class="titletext"]/text()
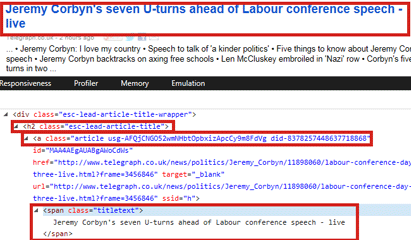
Step 5: The element path identified in the previous step is passed to the xpath function which returns a list containing all such elements in the page.
Step 6: Finally you print the list items separated by a new line.
Program source code
# # Program Name: NewsScrape.py # Description: Python script to extract news headlines from Google news website # Publisher : www.opentechguides.com # Date of Publicaton: 29-Sep-2015 # License : Free to copy and modify # from lxml import html import requests # Send request to get the web page response = requests.get('http://news.google.com') # Check if the request succeeded (response code 200) if (response.status_code == 200): # Parse the html from the webpage pagehtml = html.fromstring(response.text) # search for news headlines news = pagehtml.xpath('//h2[@class="esc-lead-article-title"] \ /a/span[@class="titletext"]/text()') # Print each news item in a new line print("\n".join(news))
Sample Output
Jeremy Corbyn's seven U-turns ahead of Labour conference speech - live Who would Russia bomb in Syria? Fifa: Jack Warner banned for life from football activities Four Britons fighting with Islamic State sanctioned by UN Drunken British architects facing obscenity charges for cavorting naked in Afghan forces battle to regain control of city after stunning loss Yemen conflict: Wedding attack death toll rises to 130 UN peacekeepers: How many personnel does each country contribute? Indonesia offers body identification assistance to Saudi Arabia Isis claims responsibility for death of Italian man in Bangladesh Sun reporter Mazher Mahmood charged with conspiracy to pervert course of justice Cereal Killer cafe protesters revealed as middle class academics Lib Dem MP Alistair Carmichael to face questions in election court Stormont crisis: Cross-party talks set to move into second week



